What you already did:
- create ML algorithms,
- create Django web service, with ML code, database models for endpoints, algorithms, and requests.
- create predict view, which is routing requests to ML algorithms.
What you will learn in this chapter:
- add a second ML algorithm (Extra Trees based) to the web service,
- create database model and REST API view for A/B tests information,
- write a python script for sending requests.
Add second ML algorithm
We will add code and tests for the Extra Trees based algorithm. Please add new file extra_trees.py in backend/server/apps/ml/income_classifer directory. (The code is very similar to RandomForestClassifier class but to keep it simple I just copy it and change the path for reading the model. There can be used inheritance here.).
# file backend/server/apps/ml/income_classifier/extra_trees.py
import joblib
import pandas as pd
class ExtraTreesClassifier:
def __init__(self):
path_to_artifacts = "../../research/"
self.values_fill_missing = joblib.load(path_to_artifacts + "train_mode.joblib")
self.encoders = joblib.load(path_to_artifacts + "encoders.joblib")
self.model = joblib.load(path_to_artifacts + "extra_trees.joblib")
def preprocessing(self, input_data):
# JSON to pandas DataFrame
input_data = pd.DataFrame(input_data, index=[0])
# fill missing values
input_data.fillna(self.values_fill_missing)
# convert categoricals
for column in [
"workclass",
"education",
"marital-status",
"occupation",
"relationship",
"race",
"sex",
"native-country",
]:
categorical_convert = self.encoders[column]
input_data[column] = categorical_convert.transform(input_data[column])
return input_data
def predict(self, input_data):
return self.model.predict_proba(input_data)
def postprocessing(self, input_data):
label = "<=50K"
if input_data[1] > 0.5:
label = ">50K"
return {"probability": input_data[1], "label": label, "status": "OK"}
def compute_prediction(self, input_data):
try:
input_data = self.preprocessing(input_data)
prediction = self.predict(input_data)[0] # only one sample
prediction = self.postprocessing(prediction)
except Exception as e:
return {"status": "Error", "message": str(e)}
return prediction
Add the test in backend/server/apps/ml/tests.py file:
# in file backend/server/apps/ml/tests.py
# add new import
from apps.ml.income_classifier.extra_trees import ExtraTreesClassifier
# ... the rest of the code
# add new test method to MLTests class
def test_et_algorithm(self):
input_data = {
"age": 37,
"workclass": "Private",
"fnlwgt": 34146,
"education": "HS-grad",
"education-num": 9,
"marital-status": "Married-civ-spouse",
"occupation": "Craft-repair",
"relationship": "Husband",
"race": "White",
"sex": "Male",
"capital-gain": 0,
"capital-loss": 0,
"hours-per-week": 68,
"native-country": "United-States"
}
my_alg = ExtraTreesClassifier()
response = my_alg.compute_prediction(input_data)
self.assertEqual('OK', response['status'])
self.assertTrue('label' in response)
self.assertEqual('<=50K', response['label'])
To run tests:
# please run in backend/server directory
python manage.py test apps.ml.tests
The algorithm is working as expected. We need to add it to our ML registry. We need to modify backend/server/server/wsgi.py file:
# the `backend/server/server/wsgi.py file
import os
from django.core.wsgi import get_wsgi_application
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'server.settings')
application = get_wsgi_application()
# ML registry
import inspect
from apps.ml.registry import MLRegistry
from apps.ml.income_classifier.random_forest import RandomForestClassifier
from apps.ml.income_classifier.extra_trees import ExtraTreesClassifier # import ExtraTrees ML algorithm
try:
registry = MLRegistry() # create ML registry
# Random Forest classifier
rf = RandomForestClassifier()
# add to ML registry
registry.add_algorithm(endpoint_name="income_classifier",
algorithm_object=rf,
algorithm_name="random forest",
algorithm_status="production",
algorithm_version="0.0.1",
owner="Piotr",
algorithm_description="Random Forest with simple pre- and post-processing",
algorithm_code=inspect.getsource(RandomForestClassifier))
# Extra Trees classifier
et = ExtraTreesClassifier()
# add to ML registry
registry.add_algorithm(endpoint_name="income_classifier",
algorithm_object=et,
algorithm_name="extra trees",
algorithm_status="testing",
algorithm_version="0.0.1",
owner="Piotr",
algorithm_description="Extra Trees with simple pre- and post-processing",
algorithm_code=inspect.getsource(RandomForestClassifier))
except Exception as e:
print("Exception while loading the algorithms to the registry,", str(e))
To see changes, please restart the server:
# please run in backend/server
# stop server with CONTROL-C.
# start server:
python manage.py runserver
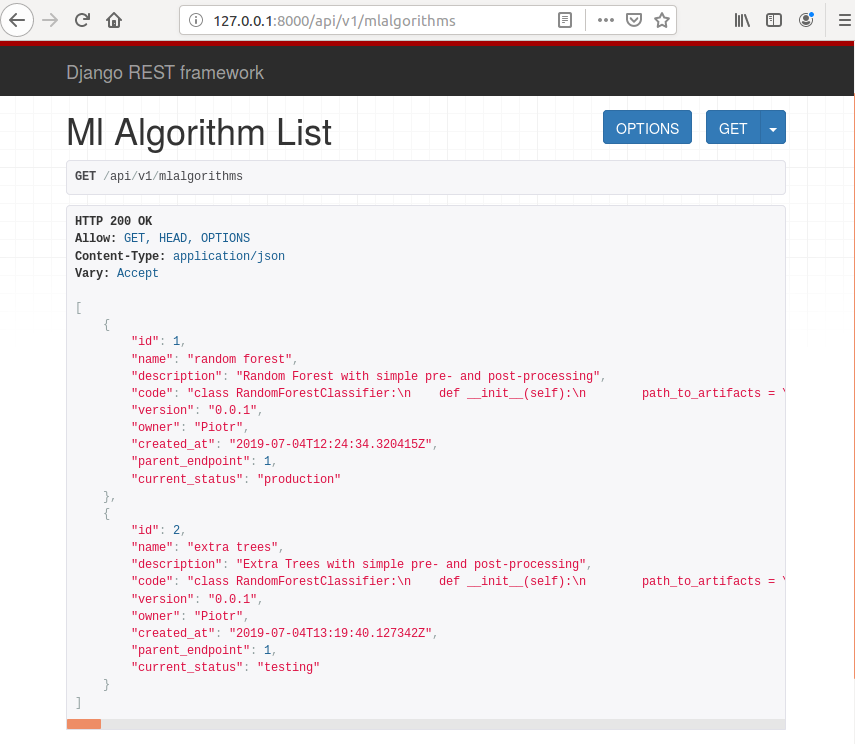
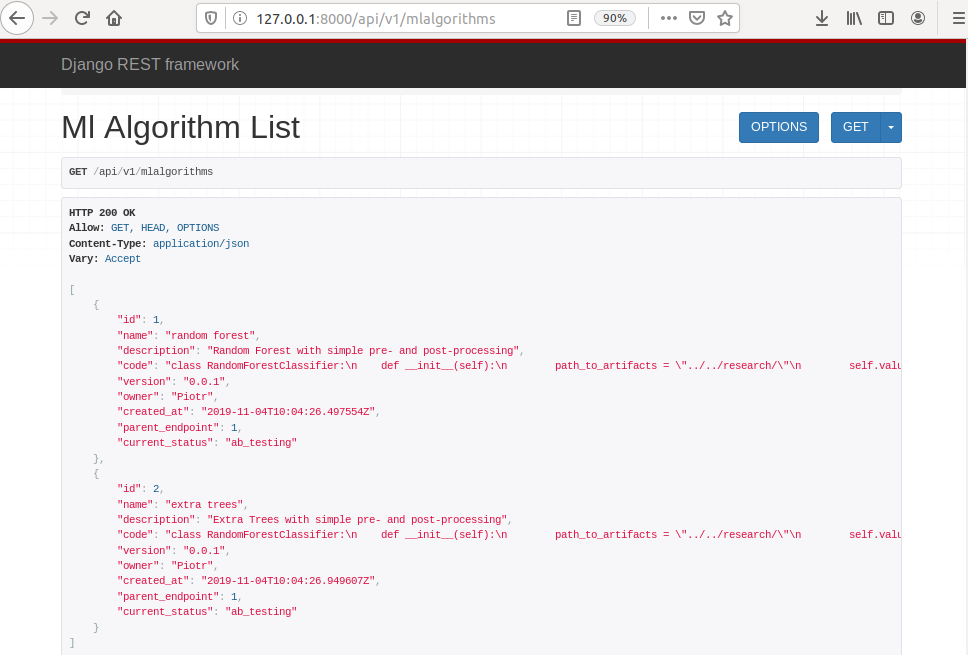
After server restart please open http://127.0.0.1:8000/api/v1/mlalgorithms in the web browser. You should see two registered ML algorithms.
Create A/B model in the database
Add ABTest model
Let’s add database model in the backend/server/apps/endpoints/models.py file to keep information about A/B tests:
# please add at the end of file backend/server/apps/endpoints/models.py
class ABTest(models.Model):
'''
The ABTest will keep information about A/B tests.
Attributes:
title: The title of test.
created_by: The name of creator.
created_at: The date of test creation.
ended_at: The date of test stop.
summary: The description with test summary, created at test stop.
parent_mlalgorithm_1: The reference to the first corresponding MLAlgorithm.
parent_mlalgorithm_2: The reference to the second corresponding MLAlgorithm.
'''
title = models.CharField(max_length=10000)
created_by = models.CharField(max_length=128)
created_at = models.DateTimeField(auto_now_add=True, blank=True)
ended_at = models.DateTimeField(blank=True, null=True)
summary = models.CharField(max_length=10000, blank=True, null=True)
parent_mlalgorithm_1 = models.ForeignKey(MLAlgorithm, on_delete=models.CASCADE, related_name="parent_mlalgorithm_1")
parent_mlalgorithm_2 = models.ForeignKey(MLAlgorithm, on_delete=models.CASCADE, related_name="parent_mlalgorithm_2")
The ABTest keeps information about:
- which ML algorithms are tested,
- who and when created the test,
- when test is stopped,
- the test results in the
summaryfield.
Define serializer
Let’s add a serializer for the ABTest model.
# please add at the beginning of file backend/server/apps/endpoints/serializers.py
from apps.endpoints.models import ABTest
# ...
# rest of the code
# ...
# please add at the end of file backend/server/apps/endpoints/serializers.py
class ABTestSerializer(serializers.ModelSerializer):
class Meta:
model = ABTest
read_only_fields = (
"id",
"ended_at",
"created_at",
"summary",
)
fields = (
"id",
"title",
"created_by",
"created_at",
"ended_at",
"summary",
"parent_mlalgorithm_1",
"parent_mlalgorithm_2",
)
Please notice, that id, created_at, ended_at and summary fields are marked as read-only. We will allow users to create A/B tests with REST API the read-only fields with be set with server code.
Define view
# please add to the file backend/server/apps/endpoints/views.py
from django.db import transaction
from apps.endpoints.models import ABTest
from apps.endpoints.serializers import ABTestSerializer
class ABTestViewSet(
mixins.RetrieveModelMixin, mixins.ListModelMixin, viewsets.GenericViewSet,
mixins.CreateModelMixin, mixins.UpdateModelMixin
):
serializer_class = ABTestSerializer
queryset = ABTest.objects.all()
def perform_create(self, serializer):
try:
with transaction.atomic():
instance = serializer.save()
# update status for first algorithm
status_1 = MLAlgorithmStatus(status = "ab_testing",
created_by=instance.created_by,
parent_mlalgorithm = instance.parent_mlalgorithm_1,
active=True)
status_1.save()
deactivate_other_statuses(status_1)
# update status for second algorithm
status_2 = MLAlgorithmStatus(status = "ab_testing",
created_by=instance.created_by,
parent_mlalgorithm = instance.parent_mlalgorithm_2,
active=True)
status_2.save()
deactivate_other_statuses(status_2)
except Exception as e:
raise APIException(str(e))
The ABTestViewSet view allows the user to create new objects. The perform_create method creates the ABTest object and two new statuses for ML algorithms. The new statuses are set to ab_testing.
We will add also a view to stop the A/B test.
# please add to the file backend/server/apps/endpoints/views.py
from django.db.models import F
import datetime
class StopABTestView(views.APIView):
def post(self, request, ab_test_id, format=None):
try:
ab_test = ABTest.objects.get(pk=ab_test_id)
if ab_test.ended_at is not None:
return Response({"message": "AB Test already finished."})
date_now = datetime.datetime.now()
# alg #1 accuracy
all_responses_1 = MLRequest.objects.filter(parent_mlalgorithm=ab_test.parent_mlalgorithm_1, created_at__gt = ab_test.created_at, created_at__lt = date_now).count()
correct_responses_1 = MLRequest.objects.filter(parent_mlalgorithm=ab_test.parent_mlalgorithm_1, created_at__gt = ab_test.created_at, created_at__lt = date_now, response=F('feedback')).count()
accuracy_1 = correct_responses_1 / float(all_responses_1)
print(all_responses_1, correct_responses_1, accuracy_1)
# alg #2 accuracy
all_responses_2 = MLRequest.objects.filter(parent_mlalgorithm=ab_test.parent_mlalgorithm_2, created_at__gt = ab_test.created_at, created_at__lt = date_now).count()
correct_responses_2 = MLRequest.objects.filter(parent_mlalgorithm=ab_test.parent_mlalgorithm_2, created_at__gt = ab_test.created_at, created_at__lt = date_now, response=F('feedback')).count()
accuracy_2 = correct_responses_2 / float(all_responses_2)
print(all_responses_2, correct_responses_2, accuracy_2)
# select algorithm with higher accuracy
alg_id_1, alg_id_2 = ab_test.parent_mlalgorithm_1, ab_test.parent_mlalgorithm_2
# swap
if accuracy_1 < accuracy_2:
alg_id_1, alg_id_2 = alg_id_2, alg_id_1
status_1 = MLAlgorithmStatus(status = "production",
created_by=ab_test.created_by,
parent_mlalgorithm = alg_id_1,
active=True)
status_1.save()
deactivate_other_statuses(status_1)
# update status for second algorithm
status_2 = MLAlgorithmStatus(status = "testing",
created_by=ab_test.created_by,
parent_mlalgorithm = alg_id_2,
active=True)
status_2.save()
deactivate_other_statuses(status_2)
summary = "Algorithm #1 accuracy: {}, Algorithm #2 accuracy: {}".format(accuracy_1, accuracy_2)
ab_test.ended_at = date_now
ab_test.summary = summary
ab_test.save()
except Exception as e:
return Response({"status": "Error", "message": str(e)},
status=status.HTTP_400_BAD_REQUEST
)
return Response({"message": "AB Test finished.", "summary": summary})
The StopABTestView stops the A/B test and compute the accuracy (ratio of correct responses) for each algorithm.
The algorithm with higher accurcy is set as production algorithm, the other algorithm is saved with testing status.
Add URL router for ABTest
The last thing is to add the URL router:
# the backend/server/apps/endpoints/urls.py file
from django.conf.urls import url, include
from rest_framework.routers import DefaultRouter
from apps.endpoints.views import EndpointViewSet
from apps.endpoints.views import MLAlgorithmViewSet
from apps.endpoints.views import MLAlgorithmStatusViewSet
from apps.endpoints.views import MLRequestViewSet
from apps.endpoints.views import PredictView
from apps.endpoints.views import ABTestViewSet
from apps.endpoints.views import StopABTestView
router = DefaultRouter(trailing_slash=False)
router.register(r"endpoints", EndpointViewSet, basename="endpoints")
router.register(r"mlalgorithms", MLAlgorithmViewSet, basename="mlalgorithms")
router.register(r"mlalgorithmstatuses", MLAlgorithmStatusViewSet, basename="mlalgorithmstatuses")
router.register(r"mlrequests", MLRequestViewSet, basename="mlrequests")
router.register(r"abtests", ABTestViewSet, basename="abtests")
urlpatterns = [
url(r"^api/v1/", include(router.urls)),
url(
r"^api/v1/(?P<endpoint_name>.+)/predict$", PredictView.as_view(), name="predict"
),
url(
r"^api/v1/stop_ab_test/(?P<ab_test_id>.+)", StopABTestView.as_view(), name="stop_ab"
),
]
OK, we are almost set. Before starting a development server we need to create and apply database migrations:
python manage.py makemigrations
python manage.py migrate
Let’s run the server:
# please run in backend/server
python manage.py runserver
You should see list of DRF generated list of APIs like in image below.
Let’s start new A/B test. Please go to address http://127.0.0.1:8000/api/v1/abtests (at development environment).
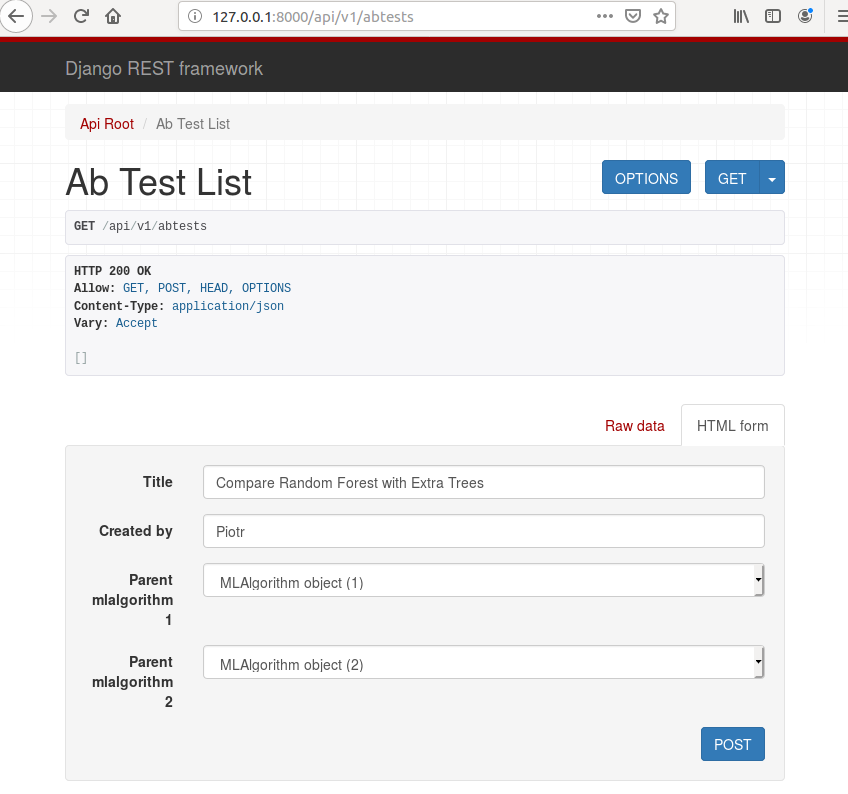
Please set the title, creator name and set algorithms. You have algorithm id in the brackets. Make sure that you select id 1 and 2, like in the image below. Press the POST button to create the test.
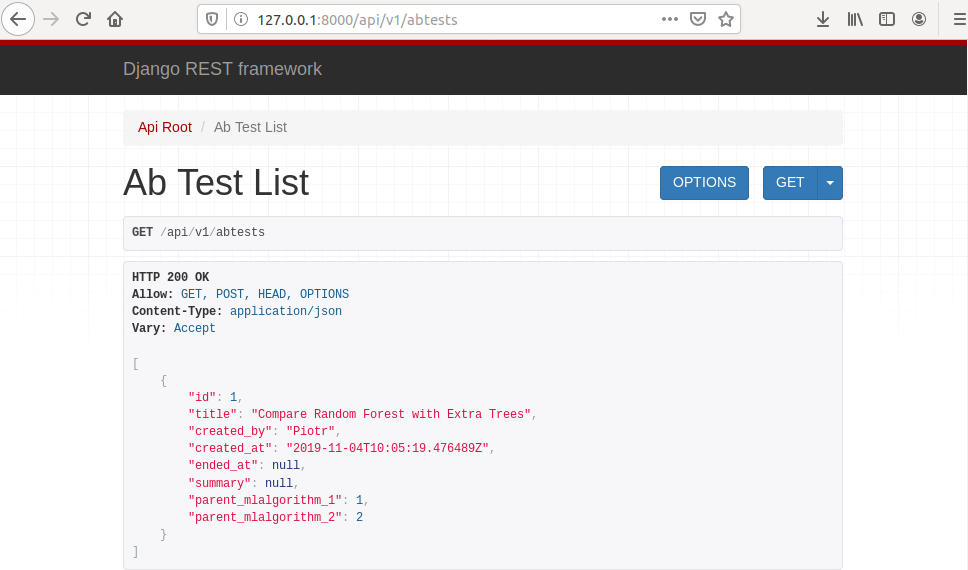
After new A/B test creation you should see view like in the image below.
After A/B test creation you should see updated status fields for ML algorithms. They should be set to ab_testing, like in the image below.
Run the A/B test
To run the A/B test we will write python script in the Jupyter notebook that will simulate real life A/B testing. The script will:
- read test data,
- send sample by sample to the server,
- get the server response and send the feedback to the server.
Before starting new notebook, please install requests package that will be used for communication with the server.
pip3 install requests
Please open Jupyter notebook and create new script ab_test.ipynb in the research directory.
Let’s add necessary packages.
import json # will be needed for saving preprocessing details
import numpy as np # for data manipulation
import pandas as pd # for data manipulation
from sklearn.model_selection import train_test_split # will be used for data split
import requests
Code to read the data:
# load dataset
df = pd.read_csv('https://raw.githubusercontent.com/pplonski/datasets-for-start/master/adult/data.csv', skipinitialspace=True)
x_cols = [c for c in df.columns if c != 'income']
# set input matrix and target column
X = df[x_cols]
y = df['income']
# show first rows of data
df.head(
Split the data to train and test sets:
# data split train / test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=1234)
Please notice that we used the same seed (random_state value) as earlier while model training.
Let’s use first 100 rows of test data for A/B test.
for i in range(100):
input_data = dict(X_test.iloc[i])
target = y_test.iloc[i]
r = requests.post("http://127.0.0.1:8000/api/v1/income_classifier/predict?status=ab_testing", input_data)
response = r.json()
# provide feedback
requests.put("http://127.0.0.1:8000/api/v1/mlrequests/{}".format(response["request_id"]), {"feedback": target})
In each iteration step, we are sending data to API endpoint:
http://127.0.0.1:8000/api/v1/income_classifier/predict?status=ab_testing
and provide feedback with true label at:
http://127.0.0.1:8000/api/v1/mlrequests/<request-id>
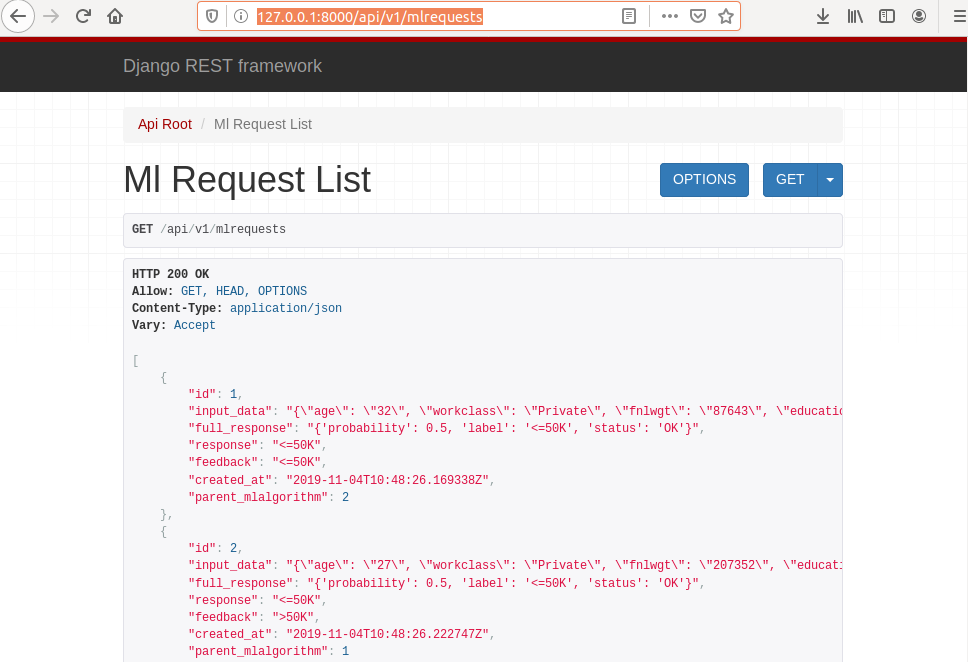
After running the script, you can check the requests at address: http://127.0.0.1:8000/api/v1/mlrequests.
You should see list of requests like in the image below.
To stop the A/B test, please open address http://127.0.0.1:8000/api/v1/stop_ab_test/1 where 1 at the end of the address it the A/B test id.
Click on POST button to finish A/B test. You should get the view like in the image below.
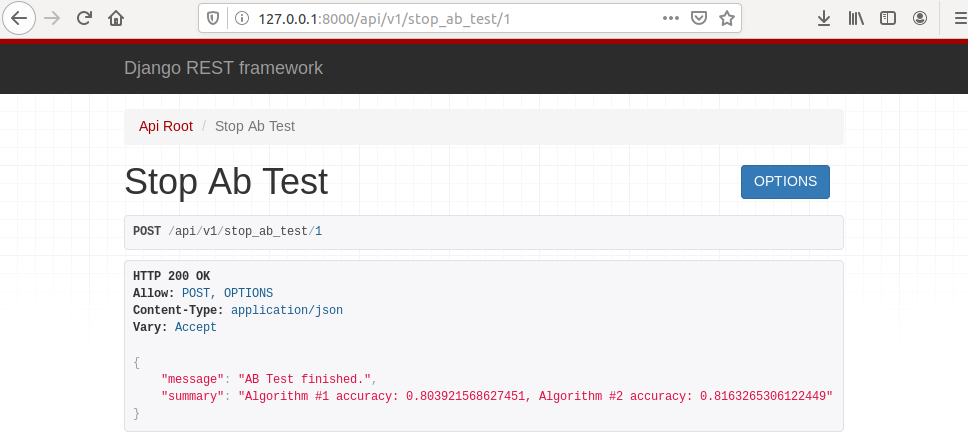
You can see that there is summary of the test displayed with accuracy for each algorithm.
You can check (at http://127.0.0.1:8000/api/v1/mlalgorithms) that algorithms have updated statuses, and the model with higher accuracy is set to production.
Add code to the repository
Let’s save our code to the repository:
git add backend/server/apps/ml/income_classifier/extra_trees.py
git add research/ab_test.ipynb
git commit -am "ab tests"
git push
In the next chapter, we will define docker container for our server.